
IO系统
7.1 键盘
¶从中断开始──键盘初体验
说起键盘,你可能想起8259A的IRQ1对应的就是键盘,在第5章中做过一个小小的试验(见代码5.57和图5.16)。那时我们没有为键盘中断指定专门的处理程序,所以当按下键盘时只能打印一行“spurious_irq:0x1”。
现在我们来写一个专门的处理程序。新建一个文件 keyboard.c,添加一个非常简单的键盘中断处理程序(代码7.1)。

结果是每按一次键,打印一个星号,像在输入密码。为了不受其他进程输出的影响,我们把其他进程的输出都注释掉。然后添加指定中断处理程序的代码并打开键盘中断(代码7.2)。

不要忘了在 proto.h 中声明 init_keyboard( ) 并调用之(代码7.3)。

¶键盘敲击的过程
在键盘中存在一枚叫做键盘编码器 Keyboard Encoder 的芯片,它通常是 Intel 8048 以及兼容芯片,作用是监视键盘的输入,并把适当的数据传送给计算机。另外,在计算机主板上还有一个键盘控制器 Keyboard Controller ,用来接收和解码来自键盘的数据,并与8259A以及软件等进行通信(如图7.3所示)。
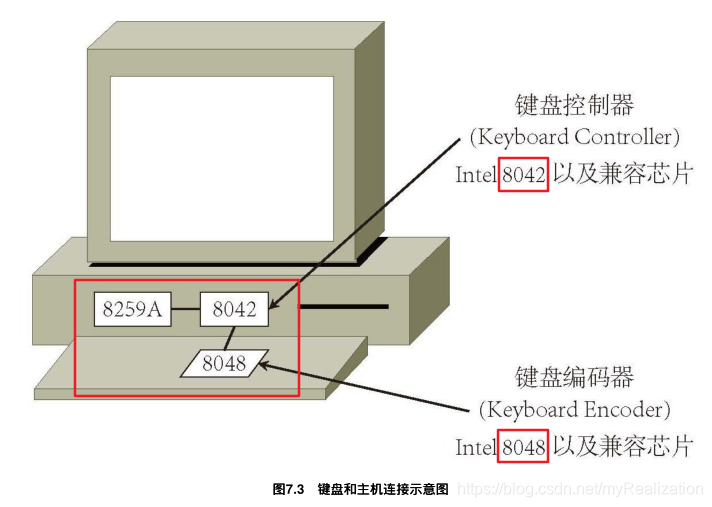
敲击键盘有两个方面的含义:动作和内容。动作可以分解成三类:按下、保持按住的状态以及放开;内容则是键盘上不同的键,字母键还是数字键,回车键还是箭头键。所以,根据敲击动作产生的编码,8048既要反映哪个按键产生了动作,还要反映产生了什么动作。
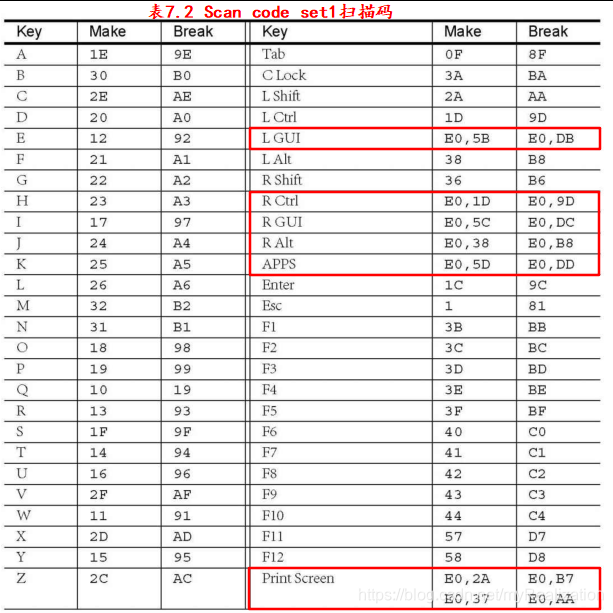
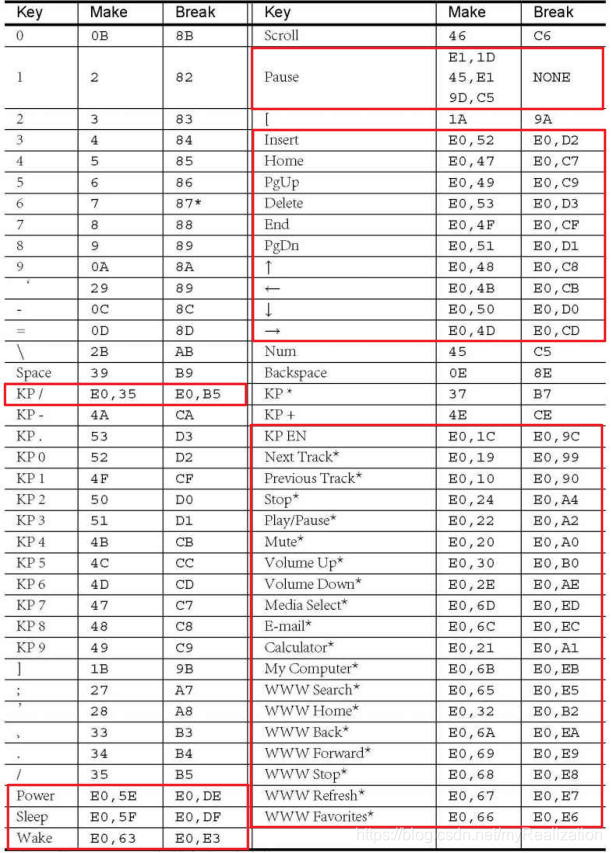
敲击键盘所产生的编码被称作扫描码 Scan Code ,它分为 Make Code 和 Break Code 两类。当一个键被按下或者保持住按下时,将会产生Make Code;当键弹起时,产生Break Code。除了Pause键之外,每一个按键都对应一个 Make Code 和一个 Break Code 。
扫描码总共有三套,叫做 Scan code set 1、Scan code set 2、Scan code set 3 。Scan code set 1 是早期的 XT 键盘使用的,现在的键盘默认都支持Scan code set 2,而 Scan code set 3 很少使用。
整个键盘输入的过程如下所示:
-
当8048检测到一个键的动作后,会把相应的扫描码发送给8042;
-
8042会把它转换成相应的
Scancode set 1扫描码,并将其放置在输入缓冲区中; -
然后8042告诉8259A产生中断 IRQ1;
-
如果此时键盘又有新的键被按下,8042将不再接收,一直到缓冲区被清空,8042才会收到更多的扫描码。
现在,你一定明白了为什么图7.1中只打印了一个字符,因为我们的键盘中断处理例程什么都没做。只有我们把扫描码从缓冲区中读出来后,8042才能继续响应新的按键。
-
由于 a 和 A 是同一个键,所以它们的扫描码是一样的,事实上它们就是同一个键)
-
如果按下 左Shift+a ,将得到这样的输出:0x2A0x1E0x9E0xAA ,分别是左Shift键的 Make Code 、a 的 Make Code 、a 的 Break Code 以及左Shift键的 Break Code 。
-
所以,按下 Shift+a 得到 A 是软件的功劳,键盘和8042是不管这些的,在你自己的操作系统中,甚至可以让 Shift+a 去对应 S 或者 T ,只要你习惯就行。
-
同理,按下任何的键,不管是单键还是组合键,想让屏幕输出什么,或者产生什么反应,都是由软件来控制的。虽然增加了操作系统的复杂性,但这种机制无疑是相当灵活的。
¶用数组表示扫描码
现在扫描码已被轻松获得,可是该如何将扫描码和相应字符对应起来呢?从表7.2中可以看出,Break Code 是 Make Code | 0x80 进行按位或操作的结果。可是 Make Code 和相应键的对应关系好像找不到什么规律。
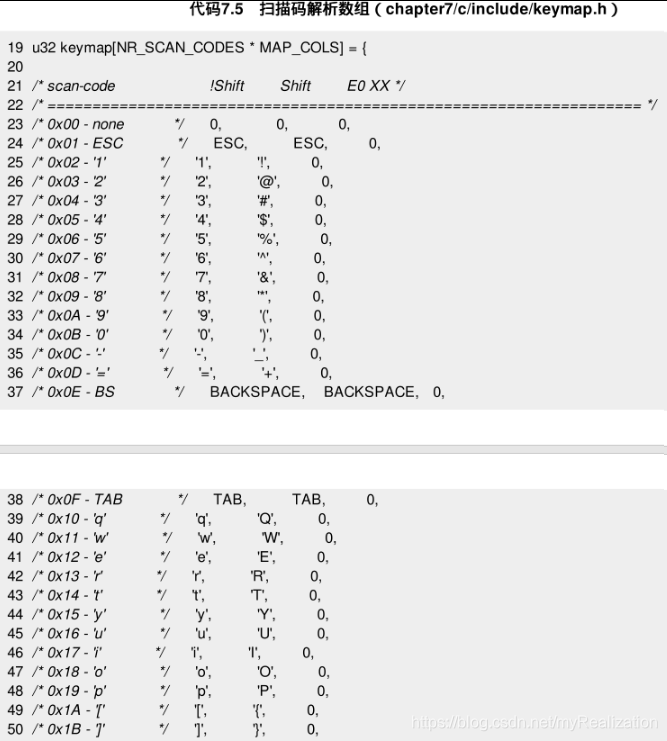
不过还好,扫描码是一些数字,我们可以建立一个数组,以扫描码为下标,对应的元素就是相应的字符。要注意的是,其中以 0xE0 以及 0xE1 开头的扫描码要区别对待。
我们把这个数组写成如下这个样子。其中每3个值一组( MAP_COLS 被定义成3),分别是单独按某键、Shift+某键和有0xE0前缀的扫描码对应的字符。Esc, Enter 等被定义成了宏,宏的具体数值无所谓,只要不会造成冲突和混淆,让操作系统认识就可以。
建立一个缓冲区,让 keyboard_handler 将每次收到的扫描码放入这个缓冲区,然后建立一个新的任务专门用来解析它们并做相应处理。如果缓冲区已满,这里使用的策略是直接就把收到的字节丢弃。
¶解析扫描码
对扫描码的解析工作有一点烦琐,所以还是分步骤来完成它。
¶1. 让字符显示出来
虽然已经有了一个数组 keymap[ ] ,但是不要低估了解析扫描码的复杂性,因为它不但分为 Make Code 和 Break Code ,而且有长有短,功能也很多样,比如 Home 键对应的是一种功能而不是一个ASCII码,所以要区别对待。先挑能打印的打印一下,看代码7.13。

在代码7.11中,总体思想是:
-
0xE0 和 0xE1 单独处理且暂时不加理会。因为从表7.2中知道,除去以这两个数字开头的扫描码,其余的都是单字节的。
-
如果遇到不是以 0xE0, 0xE1 开头的,则判断是 Make Code 还是 Break Code ,如果是后者同样不加理会,如果是前者就打印出来。
-
前文中讲过,Break Code 是 MakeCode | 0x80 进行按位或操作的结果,代码中的 FLAG_BREAK 被定义成了 0x80 。
-
从 keymap[ ] 中取出字符的时候进行了一个与操作(scan_code&0x7F 。一方面,如果当前扫描码是 Break Code ,与操作之后就变成 Make Code 了;另一方面,这样做也是为了避免越界的发生,因为数组 keymap[ ] 的大小是 0x80 。
¶2. 处理Shift、Alt、Ctrl
现在可以输入简单的字符和数字,但还有更复杂的输入,比如按个Shift组合。
下面就来添加代码,使其能够响应这些功能键。在代码7.14中,我们不但添加了处理 Shift 的代码,而且也对 Alt 和 Ctrl 键的状态进行了判断,只是暂时对它们还没有做任何的处理。


Shift, Alt, Ctrl 键左右各3个,最好不要把左右两个键不加区分,因为有一些软件需要区分对待,最简单而且经典的一个例子是超级玛丽,其中左右Shift功能是不一样的。为了不把左右键混为一谈,我们声明 6 个变量来记录它们的状态。
当其中的某一个键被按下时,相应的变量值变为 true 。比如,当我们按下左 Shift 键,shift_l 就变为 true ;
如果它立即被释放,则 shift_l 又变回 false 。
如果当左 Shift 键被按下且未被释放时,又按下 a 键,则 if (shift_l || shift_r) 成立,于是 column 值为 1 ,keymap[column] 的取值就是 keymap[ ] 中第二列中相应的值,即大写字母 A 。
7.2 显示器
随着键盘模块的逐渐完善,我们越来越需要考虑它与屏幕输出之间的关系。终端进程不仅处理键盘操作,还将处理诸如屏幕输出等内容。所以,在彻底完成键盘驱动之前,我们必须了解终端的概念以及显示器的驱动方式。
¶初识TTY(TeleTYpe)
对于终端最简单而形象的认识是,当按 Alt+F1, Alt+F2, Alt+F3 等组合键时,会切换到不同的屏幕。这些不同的屏幕中可以分别有不同的输入和输出,相互之间彼此独立。 在某个终端中,如果键入命令 tty ,执行的结果将是当前的终端号。
终端当然不仅是 Alt+Fn 这么简单,但在目前的操作系统中,我们暂时只实现这样简单的终端。对于不同的 TTY ,可以理解成下图的样式。
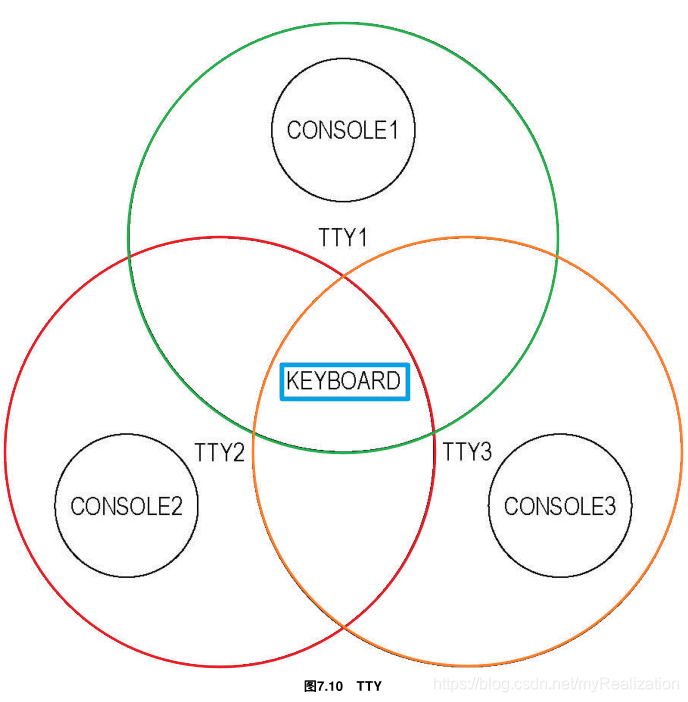
不同的 TTY 对应的输入设备虽是同一个键盘,但输出却像是在不同的显示器上,因为不同的 TTY 对应的屏幕画面可能是不同的。实际上,我们仍在使用同一个显示器,画面的不同只是因为显示了显存的不同位置。
3 个CONSOLE公用同一块显存,就必须有一种方式,在切换CONSOLE的瞬间,让屏幕显示显存中某个位置的内容。通过简单的端口操作相应的寄存器就可以做到这一点。
¶基本概念
"显示器"并不是一个精确的称呼,因为我们操作的对象可能是显卡,或者仅仅是显存。下面暂时使用"视频"这个词。
开机看到的默认模式就够了—— 80×25 文本模式, 这种模式下:
-
显存大小为 32KB ,占用的范围为 0xB8000~0xBFFFF ;
-
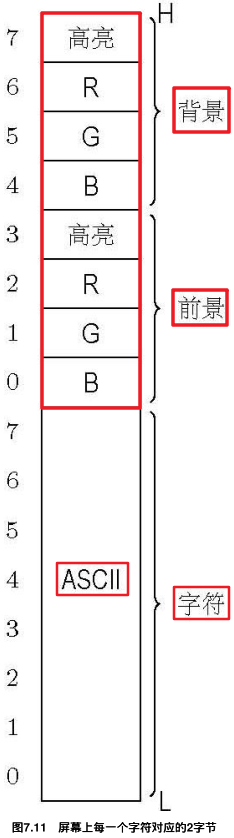
每 2 字节代表一个字符,其中低字节表示字符的ASCII码,高字节表示字符的属性——包括颜色,我们设置过字符的颜色,还写了一个函数 disp_color_str() 显示不同颜色的字符。在默认情况下,屏幕上每一个字符对应的2字节的定义如图所示:
-
一个屏幕总共可以显示 25 行,每行 80 个字符。
总的来说,屏幕字符对应的2个字节中:低字节表示的是字符本身,高字节用来定义字符的颜色。
-
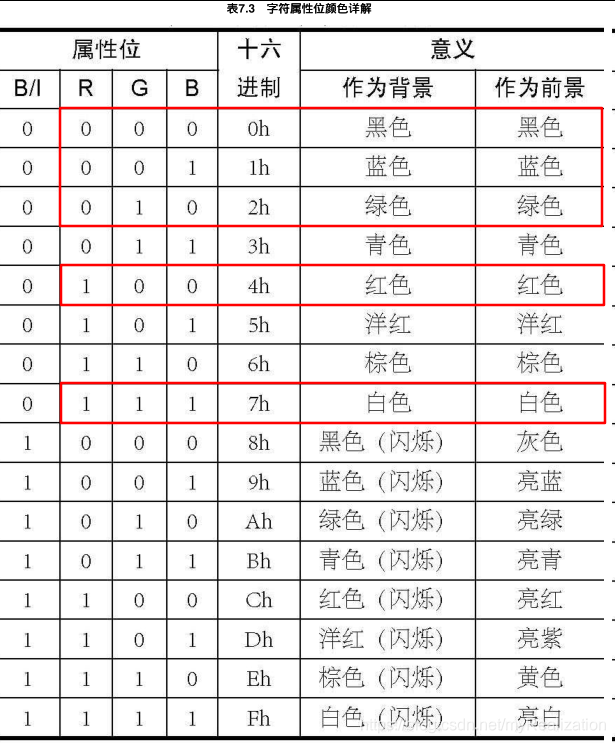
颜色分前景和背景两部分,各占4位,其中低三位意义是相同的,表示颜色。
-
如果前景最高位为 1 的话,字符的颜色会比此位为 0 时亮一些;如果背景最高位为 1 ,则显示出的字符将是闪烁的(是字符闪烁而不是背景闪烁)。
-
更多细节:
现在看第 3 章中代码 3.1 的这几行,就全明白了:
1 | mov ah, 0Ch ; 0000: 黑底; 1100: 高亮,红字 |
想实际看一下各种颜色的效果,可以通过调用 disp_color_str( ) 并改变其参数去试一下。
同时,我们已经知道一个屏幕可以显示几行几列,又知道了一个字符占用几个字节,易得一个屏幕映射到显存中所占的空间大小:80×25×2=4000 Bytes 。
而显存有 32KB ,每个屏幕才占 4KB ,所以显存中足以存放 8 个屏幕的数据。如果我们有 3 个 TTY ,可以各占 10KB 的空间还有剩余,甚至在每一个 TTY 内还可以实现简单的滚屏功能。
7.3 TTY任务
了解了键盘和显示器的操作,我们就可以实现多个TTY了,让TTY任务这样运行:
-
在TTY任务中执行循环,每次都会轮询每个TTY,处理它的事件——包括从键盘缓冲区读取数据、显示字符等;
-
不是轮询到某个TTY时,箭头对应的全部事件都会发生。只有当某个TTY对应的控制台是当前控制台时,它才可以读取键盘缓冲区;
-
TTY可以对输入数据做更多的处理,这里简化为"显示";
-
键盘和显示器是每个TTY的一部分,是公共的。
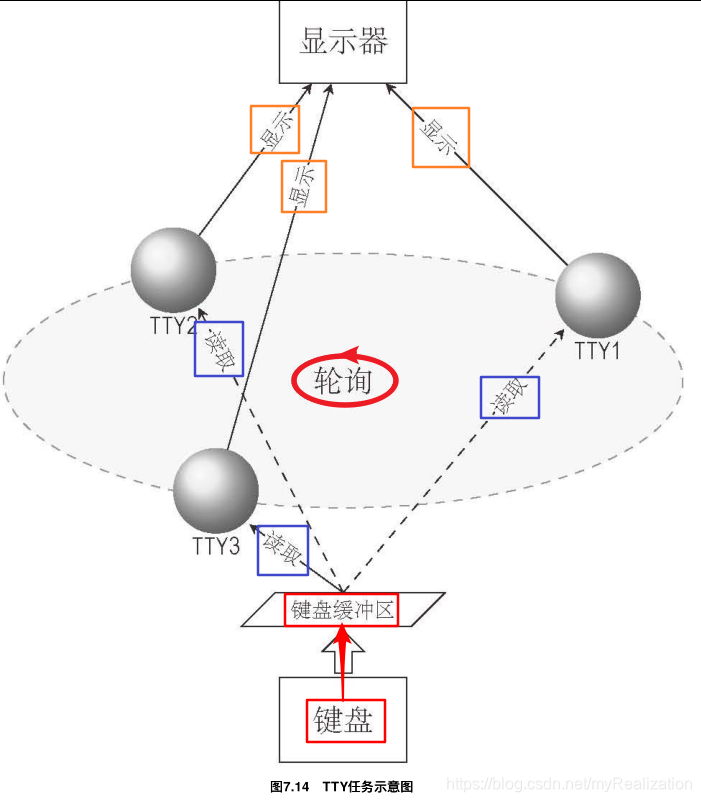
总的来说,每次轮询到某个TTY时要做的:
处理输入——如果它是当前TTY,就从键盘缓冲区读取数据;
处理输出——如果有要显示的内容,则显示它。
将上面的TTY任务图转换为下面的函数调用图:task_tty() 是一个循环,它不断调用 keyboard_read() ,而 key_board() 从键盘缓冲区得到数据后,会调用 in_process() ,将字符直接显示出来。
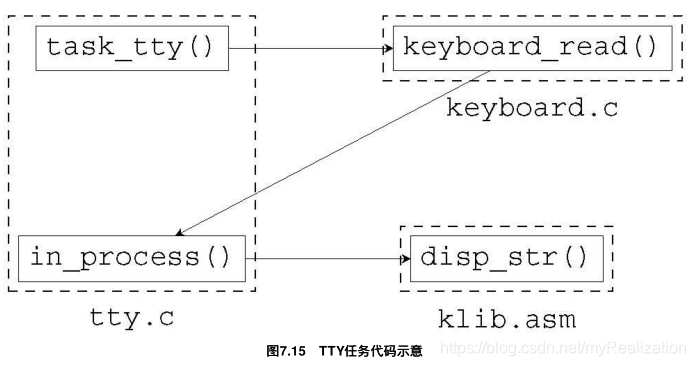
话虽如此,实现起来就不是说的那么简单了:
-
每一个TTY都应该有自己的读和写的动作。所以在 keyboard_read( ) 内部,函数需要了解自己是被哪一个TTY调用。可以通过为函数传入指向当前TTY的指针来做到这一点。
-
为了让输入和输出分离,被 keyboard_read( ) 调用的 in_process( ) 不应该再直接回显字符,应该将回显的任务交给TTY来完成,因此,我们就需要为每个TTY建立一块缓冲区,用以放置将被回显的字符。
-
每个TTY回显字符时操作的CONSOLE是不同的,所以它们都应该有一个成员来记载其对应的CONSOLE信息。
¶TTY任务框架的搭建
整个程序流程如下:
-
task_tty( ) 中,通过循环来处理每一个TTY的读和写操作;
-
读写操作全都放在 tty_do_read( ), tty_do_write( ) 两个函数中,这样就让 task_tty( ) 很简洁,而且逻辑清晰。
-
读操作会调用 keyboard_read( ) ,此时已经多了一个参数;
-
写操作会调用 out_char( ) ,它会将字符写入指定的CONSOLE。
读操作:往TTY缓冲区写入数据的代码很简单,只把输出字符写入缓冲区
写操作:从TTY缓冲区中中取出值,类似 get_byte_from_kbuf( ) ,然后用 out_char( ) 显示在CONSOLE中;out_char( ) 实现如下:V_MEM_BASE = 0xB8000 定义在 const.h 中, V_MEM_BASE + disp_pos 等同于当前显示位置的地址,我们直接把字符写入特定地址;
¶多控制台
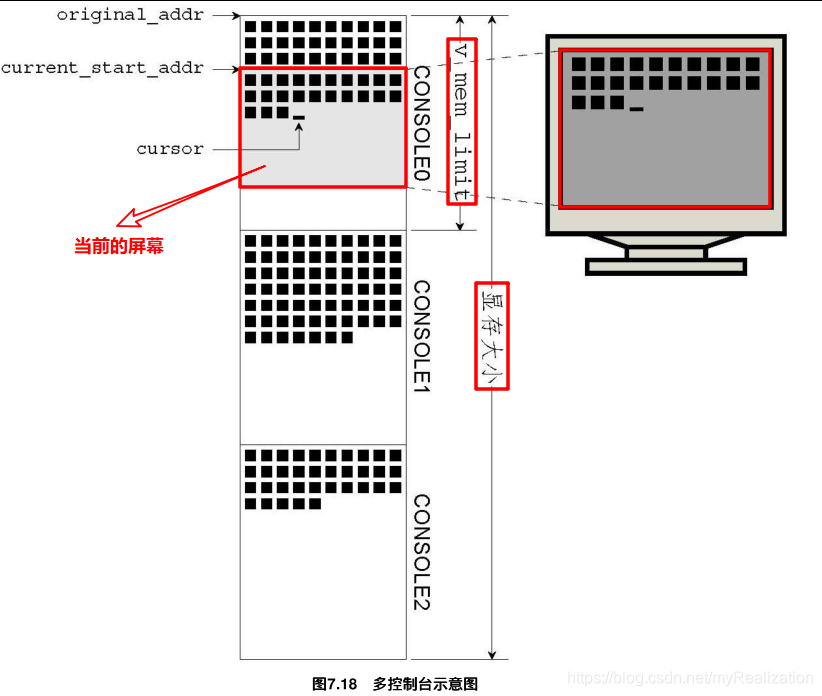
这里来实现多个CONSOLE。前面,我们还根本没有用到CONSOLE的结构体成员。下图是某时刻显存的使用状态:
original_addr, v_mem_limit 定义控制台所占显存的总体情况,一经初始就不再改变;
current_start_addr 随着屏幕卷动而变化;
cursor 每输出一个字符就更新一次;
7.4 区分任务和用户进程
现在,我们有了4个进程——TTY, A, B, C ,后三者可有可无,它们是"用户进程",而TTY是"任务"。具体实现上,让用户进程运行在 ring3 ,任务运行在 ring1 ,ring0 运行的是进程调度:

7.5 printf
现在,我们有了TTY,还有一个任务和三个用户进程,想看到它们在特定终端运行的情况。为此,我们需要有一个供输出使用的 printf( ) 。
printf( ) 进行屏幕输出,需要用到控制台模块的代码,因此,它需要通过系统调用才能完成。
整个 printf( ) 的调用过程如下:


vsprintf( ) 的实现如下:

可变参数的原理:
调用一个函数时,总是先把参数压栈,然后通过call指令转移到被调用者,在完成后清理堆栈。 但这里遇到两个问题:
如果有多个参数,哪个参数先入栈,是前面的还是后面的?
由谁来清理堆栈,调用者还是被调用者?这两个方面的问题其实被称为“调用约定”(Calling Conventions)……调用约定有若干种,每一种都规定参数入栈的顺序以及谁来清理堆栈。我们已经用汇编语言写过不少的函数,都是后面的参数先入栈(前面的参数就位于栈顶,更容易取出),并且由调用者清理堆栈。这种约定被称做C调用约定。
C调用约定的好处在处理可变参数函数时得到了充分体现,因为只有调用者知道此次调用包含几个参数,于是可以方便地清理堆栈。C调用约定让使用可变参数的函数成为可能。
可具体怎么做呢?
首先是它的声明,过去我们写的函数,都有确定类型的参数,可现在不同了,参数的个数和类型都不知道,于是,省略号就派上了用场,正如代码7.55所示,一个省略号,表示参数不知道有多少,更不知道是什么。
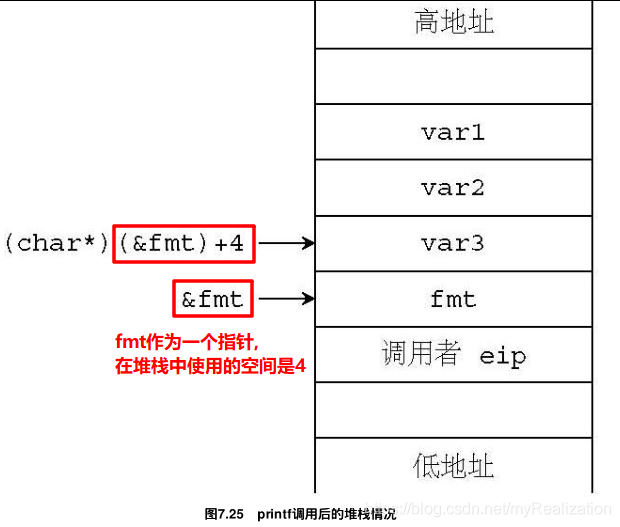
…在每一次调用过程中,printf 必须有一种方法来使用这些参数才行。从代码7.55可以看到,printf 使用了它的第一个参数 fmt 作为基准,得到了后面若干参数的开始地址,这样,其值也就容易得到了。举一个例子,假设我们调用 printf(fmt, var1, var2, var3) ,则堆栈情况将如图7.25所示:
&fmt 表示 fmt 地址,(char*)(&fmt) + 4 表示跟随在 fmt 后面的参数的地址。所以,接下来实际上是将 var3 的地址传递给了紧接着调用的 vsprintf 。va_list 其实就是 char* ,它的定义在 type.h 中。
¶系统调用write()
接下来完成 write( ) 系统调用,它把 vsprintf 输出的字符串打印到屏幕上。
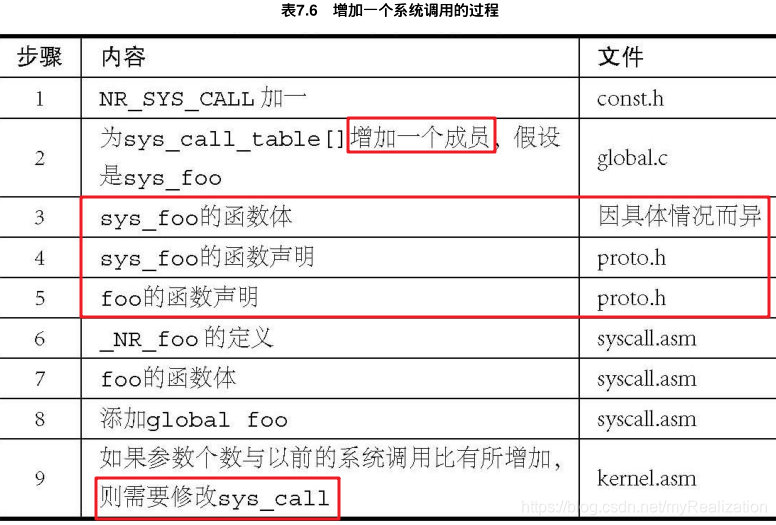
增加一个系统调用 (foo) 的过程如下:
系统调用是 write( ) ,对应的内核部分是 sys_write( ) ,声明在 proto.h 中,对应第4步和第5步:
接下来是 write( ) 和 sys_write( ) 两个函数体:由于已有的系统调用没有参数,所以还需要修改 sys_call( ) :
sys_write( ) 通过简单函数 tty_write( ) 实现字符输出,这里 sys_write( ) 比 write( ) 多一个参数,需要在修改的 sys_call( ) 中压栈,然后 sys_call 调用 sys_write :
修改的 sys_call 如下。当前运行的进程是通过设置 p_proc_ready 来恢复执行的,所以当进程切换到未发生之前, p_proc_ready 的值就是指向当前进程的指针。把它压栈就是把当前进程即 write( ) 的调用者指针传递给了 sys_write( ) :

