
jyyOS-2
¶并发的基本单位:线程
共享内存的多个执行流
- 执行流拥有独立的堆栈/寄存器
- 共享全部的内存 (指针可以互相引用)
入门:thread.h 简化的线程 API
create(fn)- 创建一个入口函数是
fn的线程,并立即开始执行void fn(int tid) { ... }- 参数
tid从 1 开始编号
- 语义:在状态中新增 stack frame 列表并初始化为
fn(tid)
- 创建一个入口函数是
join()- 等待所有运行线程的
fn返回 - 在
main返回时会自动等待所有线程结束 - 语义:在有其他线程未执行完时死循环,否则返回
- 等待所有运行线程的
- 编译时需要增加
-lpthread
1 |
|
放弃
¶1. 原子性
1 |
|
“程序 (甚至是一条指令) 独占处理器执行” 的基本假设在现代多处理器系统上不再成立。
原子性:一段代码执行 (例如 pay()) 独占整个计算机系统
- 单处理器多线程
- 线程在运行时可能被中断,切换到另一个线程执行
- 多处理器多线程
- 线程根本就是并行执行的
¶2. 顺序
给sum添加编译优化?
-O1: 100000000 😱😱-O2: 200000000 😱😱😱
不同编译优化对并发的处理不同,O1可能是分别写入各自求和的结果
编译器对内存访问 “eventually consistent” 的处理导致共享内存作为线程同步工具的失效。
¶3. 可见性
1 | int x = 0, y = 0; |
出现了状态机推理之外的结果:0 0
现代处理器也是(动态)编译器,把汇编变为微指令μops,每个μop都有Fetch, Issue, Execute, Commit 四个阶段。
满足单处理器 eventual memory consistency 的执行,在多处理器上可能无法序列化!
导致可见性的丧失
互斥
¶一个互斥算法——Peterson 算法
互斥:保证两个线程不能同时执行一段代码。
¶举例
A 和 B 争用厕所的包厢
-
想进入包厢之前,A/B 都要先举起自己的旗子
-
A 确认旗子举好以后,往厕所门上贴上 “B 正在使用” 的标签
B 确认旗子举好以后,往厕所门上贴上 “A 正在使用” 的标签
-
然后,如果对方的旗子举起来,且门上的名字不是自己,等待
否则可以进入包厢
-
出包厢后,放下自己的旗子
- 如果只有一个人举旗,他就可以直接进入
- 如果两个人同时举旗,由厕所门上的标签决定谁进
- 手快有 (被另一个人的标签覆盖)、手慢无
¶硬件提供原子指令
例:Atomic exchange (load + store)
1 | int xchg(volatile int *addr, int newval) { |
原子指令的模型
- 保证之前的 store 都写入内存
- 保证 load/store 不与原子指令乱序
¶自旋锁
¶用 xchg 实现互斥
如何协调宿舍若干位同学上厕所问题?
- 在厕所门口放一个桌子 (共享变量)
- 初始时,桌上是 🔑
- 每个人可以完成原子操作
- 拿一个任意东西与🔑交换(xchg)
实现互斥的协议
- 想上厕所的同学 (一条 xchg 指令)
- 天黑请闭眼
- 试图知道桌子上有什么 (🔑 或 🔞)
- 把 🔞 放到桌上 (覆盖之前有的任何东西)
- 天亮请睁眼;看到 🔑 才可以进厕所哦
- 出厕所的同学
- 把 🔑 放到桌上
1 | int table = YES; |
¶Load-Reserved/Store-Conditional (LR/SC)
LR: 在内存上标记 reserved (盯上你了),中断、其他处理器写入都会导致标记消除
SC: 如果 “盯上” 未被解除,则写入
¶自旋锁的缺陷
因为自旋锁的存在使得临界区的代码只能被串行执行,拿不到所的线程只能在CPU上空转,所以程序的性能受到了不小的影响,因此自旋锁一般用于管理比较短的临界区
即:
-
自旋 (共享变量) 会触发处理器间的缓存同步,延迟增加
-
- 除了进入临界区的线程,其他处理器上的线程都在空转
- 争抢锁的处理器越多,利用率越低
-
获得自旋锁的线程可能被操作系统切换出去,100%资源浪费
¶自旋锁的使用场景
- 临界区几乎不 “拥堵”
- 持有自旋锁时禁止执行流切换
使用场景:操作系统内核的并发数据结构 (短临界区)
¶mutex(互斥锁/睡眠锁)
因此,我们要改进自旋锁的性能,从“程序就是状态机”的视角来看,拿不到自旋锁的线程所对应的状态机只会不可避免的一遍一遍地执行xchg指令,那我们不妨想办法修改它的状态机,让它在第一次尝试获得锁失败后就立刻执行syscall指令,陷入内核,让拥有高特权级的操作系统内核把其他线程换上CPU运行,就好像这个线程已经用完了它的时间片。这样的话,既不会改变状态机原有的状态,也把CPU资源留给了有用的计算。
syscall(SYSCALL_lock, &lk);- 试图获得
lk,但如果失败,就切换到其他线程
- 试图获得
syscall(SYSCALL_unlock, &lk);- 释放
lk,如果有等待锁的线程就唤醒
- 释放
举例:操作系统 = 更衣室管理员
- 先到的人 (线程)
- 成功获得手环,进入游泳馆
*lk = 🔒,系统调用直接返回
- 后到的人 (线程)
- 不能进入游泳馆,排队等待
- 线程放入等待队列,执行线程切换 (yield)
- 洗完澡出来的人 (线程)
- 交还手环给管理员;管理员把手环再交给排队的人
- 如果等待队列不空,从等待队列中取出一个线程允许执行
- 如果等待队列为空,
*lk = ✅
- 管理员 (OS) 使用自旋锁确保自己处理手环的过程是原子的
¶自旋锁·睡眠锁分析
自旋锁 (线程直接共享 locked)
- 更快的 fast path
- xchg 成功 → 立即进入临界区,开销很小
- 更慢的 slow path
- xchg 失败 → 浪费 CPU 自旋等待
在多处理器情况下,没有对锁的争用,也就是只有一个线程想获得锁,那么明显自旋锁更快,通过一条xchg原子指令就能获得/释放锁;如果出现了锁的争用,拥堵的越严重,自旋锁的性能就越差。
睡眠锁 (通过系统调用访问 locked)
- 更快的 slow path
- 上锁失败线程不再占用 CPU
- 更慢的 fast path
- 即便上锁成功也需要进出内核 (syscall)
- 系统调用涉及到特权级的切换,页表的切换,栈指针的切换,etc. 系统调用这件事本身的开销就不小
¶Futex: Fast Userspace muTexes
- Fast path: 一条原子指令,上锁成功立即返回
- Slow path: 上锁失败,执行系统调用睡眠
同步
线程同步:在某个时间点共同达到互相已知的状态
¶生产者-消费者问题
并发软件开发场景中,有相当大一部分的并发问题本质上就是生产者-消费者问题。
概述如下:有一个buffer,它的大小是固定的,此时系统中有两种类型的线程;
- 生产者(producer),往buffer里丢东西
- 消费者(consumer),从buffer里取东西
因为buffer有大小限制,所以不能往里面丢太多东西,因此生产者在buffer满的时候就不能向其中再填入数据了,需要开始等待;当buffer空的时候,消费者也自然不会消费,因此也需要开始等待。
1 | void Tproduce() { |
用互斥锁保持条件成立,但它还是有一个自旋的循环,尽管lock中不一定spin,但while循环做的事情就是spin,可以说是"spin on the buffer"
¶条件变量:万能同步方法
条件变量的设计,其实就是“锁+条件”
把上文代码中的自旋变成睡眠,在完成操作时唤醒
¶条件变量 API
-
wait(cv, mutex) 💤
- 调用时必须保证已经获得 mutex
- 释放 mutex、进入睡眠状态
wait(fn)这种,该api会一直监控fn,频繁地调用它,看它满足不满足条件,其内部实现可以是while(!fn());这样,所以看起来我们就可以保证“wait返回之后,fn对应的条件就成立了”。实则不然,这只能保证
fn被调用的时候条件成立,但系统是并发的(可能有好几百个生产者/消费者),fn返回的时候也许条件就不再成立了,因此api不能这样设计。我们希望的是
wait返回之后,相应的条件会在一段时间里持续地被满足,因此可以借助锁使得条件持续地被满足。条件变量的设计,其实就是“锁+条件”因此,
wait函数内部要做的事情就是:当发现条件不满足时进入睡眠,并且释放锁,等到条件满足时线程被唤醒,并且再次获得锁,从而在保持条件一直被满足,直到锁被释放。
-
signal/notify(cv) 💬 私信:走起
- 如果有线程正在等待 cv,则唤醒其中一个线程
-
broadcast/notifyAll(cv) 📣 所有人:走起
- 唤醒全部正在等待 cv 的线程
具体的代码框架如下,cond是我们要等待的条件。如果我们知道每个线程在等什么,并且能够知道其他的线程在什么时候可以让这个线程所等待的事情成立,就可以套用如下的框架去解决同步问题
-
需要等待条件满足时
mutex_lock(&mutex); while (!cond) { wait(&cv, &mutex); } assert(cond); // ... // 互斥锁保证了在此期间条件 cond 总是成立 // ... mutex_unlock(&mutex); -
其他线程条件可能被满足时
broadcast(&cv);
¶习题
有三种线程,分别打印 <, >, 和 _
- 对这些线程进行同步,使得打印出的序列总是
<><_和><>_组合
使用条件变量,实现多个打印线程之间的同步,那么就需要分析出:每个线程得以继续向前执行时需要满足什么条件?
也就是只要回答三个问题:
- 打印 “
<” 的条件? - 打印 “
>” 的条件? - 打印 “
_” 的条件?
给我们期望中的系统构建一个状态机
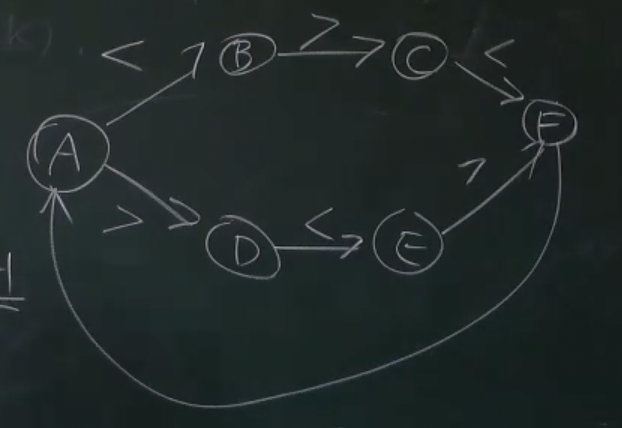
1 | enum state { |
信号量(semaphore)
信号量的工作机制,可以直接理解成计数器(当然其实加锁的时候肯定不能这么简单,不只只是信号量了),信号量会有初值(>0),每当有进程申请使用信号量,通过一个P操作来对信号量进行-1操作,当计数器减到0的时候就说明没有资源了,其他进程要想访问就必须等待(具体怎么等还有说法,比如忙等待或者睡眠),当该进程执行完这段工作(我们称之为临界区)之后,就会执行V操作来对信号量进行+1操作。
临界区:临界区指的是一个访问共用资源(例如:共用设备或是共用存储器)的程序片段,而这些共用资源又无法同时被多个线程访问的特性。
临界资源:只能被一个进程同时使用(不可以多个进程共享),要用到互斥。
信号量也是进程间通信的一种方式,比如互斥锁的简单实现就是信号量,一个进程使用互斥锁,并通知(通信)其他想要该互斥锁的进程,阻止他们的访问和使用。
¶行为建模
Dijkstra提出,故术语PV操作出自荷兰文
- P(&sem) - prolaag = try + decrease; wait; down; in
- 等待一个手环后返回
- 如果此时管理员手上有空闲的手环,立即返回
- V(&sem) - verhoog = increase; post; up; out
- 变出一个手环,送给管理员
当有进程要求使用共享资源时,需要执行以下操作:
1.系统首先要检测该资源的信号量;
2.若该资源的信号量值大于0,则进程可以使用该资源,此时,进程将该资源的信号量值减1;
3.若该资源的信号量值为0,则进程进入休眠状态,直到信号量值大于0时进程被唤醒,访问该资源;
当进程不再使用由一个信号量控制的共享资源时,该信号量值增加1(V),如果此时有进程处于休眠状态等待此信号量,则该进程会被唤醒。
现代编程语言中的并发模型
¶协程(coroutines)
- 多个可以保存/恢复的执行流
- 比线程更轻量 (完全没有系统调用,也就没有操作系统状态)
在一个没有多线程的程序里面,创建出若干个好像线程的东西。co_start(fn)会在内存中创建一个执行流fn,但是系统当中还是只有一个执行流在执行:先是一直执行main的代码,直至执行co_yield(),暂停当前的执行流,然后切换到另外一个执行流,该执行流从fn开始执行,fn执行完了之后会再次执行co_yield,就会回到之前的执行流去执行。
协程和线程相比,坏处是无法使用多个CPU,无并行可言。
好处是,如果我们希望函数执行的时候帮我们算一个东西出来,并且执行流离开它时函数的状态可以得到保存,下一次执行流再切换回这个函数的时候它可以给我们计算出下一个东西,那么就可以使用协程来完成,Python的Generator就是这样的协程。
¶数据中心:协程和线程
数据中心
- 同一时间有数千/数万个请求到达服务器
- 计算部分
- 需要利用好多处理器
- 线程 → 这就是我擅长的
- 协程 → 一人出力,他人摸鱼
- 需要利用好多处理器
- I/O 部分
- 会在系统调用上 block (例如请求另一个服务或读磁盘)
- 协程 → 一人干等,他人围观
- 线程 → 每个线程都占用可观的操作系统资源
- 会在系统调用上 block (例如请求另一个服务或读磁盘)
¶Go和Goroutine
面对协程和线程各自的问题,Goroutine应运而生,使用Go目前也成为了后端开发的趋势,兼顾多处理器并行和轻量级并发。
Goroutine: 概念上是线程,实际是线程和协程的混合体
-
在每个CPU上都放一个线程,每个 CPU 上有一个 Go Worker,自由调度 Goroutines。两个CPU上的Goroutine可以是真正并行的。任何时刻单个CPU上只会有一个Goroutine运行。
-
执行到 blocking API 时 (例如 sleep, read)
Go Worker 偷偷改成 non-blocking 的版本:要执行
read的时候,read()都会被替换成tryread()tryread()成功 → 立即继续执行Goroutinetryread()失败 → 立即 yield 到另一个需要 CPU 的 Goroutine,操作系统会提供相关的api使得它可以在条件合适的时候被唤醒。
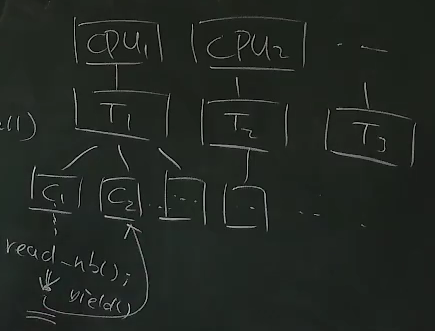
太巧妙了!CPU 和操作系统全部用到 100%
身边的并发:Web 2.0
是什么成就了今天的 Web 2.0 ?
- 浏览器中的并发编程:Ajax (Asynchronous JavaScript + XML)
- HTML (DOM Tree) + CSS 代表了你能看见的一切
- 通过 JavaScript 可以改变它
- 通过 JavaScript 可以建立连接本地和服务器
¶单线程 + 事件模型
我们需要的是尽可能少但又足够的并发。
- 一个线程、全局的事件队列、按序执行 (run-to-complete)
- 耗时的 API (Timer, Ajax, …) 调用会立即返回(网络请求和结果操作一定不是同一个事件,而是将不同的响应操作加入事件队列)
- 条件满足时向队列里增加一个事件
1 | $.ajax( { url: 'https://xxx.yyy.zzz/login', |
¶异步事件模型
好处
- 并发模型简单了很多
- 函数的执行是原子的 (不能并行,减少了并发 bug 的可能性)
- API 依然可以并行
- 适合网页这种 “大部分时间花在渲染和网络请求” 的场景
- JavaScript 代码只负责 “描述” DOM Tree
- 适合网页这种 “大部分时间花在渲染和网络请求” 的场景
坏处
- Callback hell (祖传屎山)
- 刚才的代码嵌套 5 层,可维护性已经接近于零了
导致 callback hell 的本质:人类脑袋里想的是 “流程图”,看到的是 “回调”。解决:Promise
并发bug
¶死锁(Deadlock)
¶死锁产生的四个必要条件:
- 互斥:一个资源每次只能被一个进程使用
- 请求与保持:一个进程请求资阻塞时,不释放已获得的资源
- 不剥夺:进程已获得的资源不能强行剥夺
- 循环等待:若干进程之间形成头尾相接的循环等待资源关系
¶避免死锁
- 任意时刻系统中的锁都是有限的
- 严格按照固定的顺序获得所有锁,消除 “循环等待”
¶数据竞争(Data Race)
不同的线程同时访问同一段内存,且至少有一个是写。
两个内存访问在 “赛跑”,“跑赢” 的操作先执行(如peterson算法)
¶解决
用互斥锁保护好共享数据,消灭一切数据竞争
¶例子
数据竞争相关典型的两种bug
1 | // Case #1: 上错了锁(各上个的) |
¶动态分析工具:Sanitizers
- AddressSanitizer (asan); (paper): 非法内存访问
- ThreadSanitizer (tsan): 数据竞争
- Demo: fish.c, sum.c, peterson-barrier.c; ktsan
- MemorySanitizer (msan): 未初始化的读取
- UBSanitizer (ubsan): undefined behavior
- Misaligned pointer, signed integer overflow, …
- Kernel 会带着
-fwrapv编译
¶防御性编程
Canary (金丝雀) 对一氧化碳非常敏感,被用于预警矿井下的瓦斯泄露。计算机系统中也有 canary,“牺牲” 一些内存单元,来预警 memory error 的发生。即在栈的高地址低地址两端都留出缓冲区。

